https://ekdud7667.tistory.com/42?category=897373
1-1. 타이타닉 튜토리얼1
import & data 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns plt.style.use('seaborn') sns.set(font_scale=2.5) # 이..
ekdud7667.tistory.com
1.2부터는 튜토리얼과 EDA가 겹치는 부분이 많아, 겹치는 부분은 설명 없이 진행하려 합니다. EDA의 자세한 설명은 튜토리얼 링크에서 참고하세요.
1. EDA
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
# 데이터 부르기
data=pd.read_csv('train.csv')
# 데이터 null값 확인
data.isnull().sum()
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('Survived')
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

- categorical features: Sex, Embarked
- ordinal features: Pclass
- continous features: age
label의 분포를 보면 제법 균일하다. 만약 100중 1이 99, 0이 1개인 불균형한 경우 모델이 모든 것을 1이라고 해도 정확도가 99%가 나오기 때문에 0을 찾는 문제라면 이 모델은 원하는 결과를 줄 수 없다.
또, label이 어떤 분포를 가지고 있는지에 따라 모델의 평가 방법이 달라질 수 있다고 하는데, 이와 같은 classification의 문제를 평가할 때 accuracy외에 confusion matrix등을 사용할 수 있다는 뜻인것 같다.
label의 분포를보고 데이터가 균일한가 불균일한가는 분석가의 주관적인 판단이 필요한데, 이 기준에 대해선 아직 이해를 하지못해, 추후에 공부를 할 예정이다.
2. Analysing The Feature
튜토리얼에서 진행했던 분석은 띄어넘고, 이 분석에서 특색 있는 부분만 게시했음. 이전 분석은 위의 링크를 참고
Name Analysis
|
1
2
3
4
5
|
data['Initial']=0
for i in data:
|

기타 Initial 대체
|
1
2
3
4
|
data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True)
data.groupby('Initial')['Age'].mean() #lets check the average age by Initials
|
s |

Age
- Null값 메우고 난 뒤, Survive 분석
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46
#null값 확인 -> False
data.Age.isnull().any()
f,ax=plt.subplots(1,2,figsize=(20,10))
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived= 0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
data[data['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived= 1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|

Embarked
|
1
2
3
4
|
pd.crosstab([data.Embarked,data.Pclass],[data.Sex,data.Survived],margins=True).style.background_gradient(cmap='summer_r')
# embarked의 null값을 S로 채운다
data['Embarked'].fillna('S',inplace=True)
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

EDA 결과 요약
| Sex | Women일 수록 생존율이 높다. |
| Pclass | class가 높을수록 생존율이 높다.(1st가 제일 높고, 3st가 제일 낮음) |
| Age | children(5-10살)이 가장 생존율이 높으며, 15-35살이 가장 사망률이 높다. |
| Embarked | C에서 탑승한 경우 생존율이 높다. 특히, Pclass가 1이면서 S에서 탑승한 사람보다 C에서 탑승한 사람이 더 높다. 또, Q에서 탑승한 사람은 대부분 3st이다. |
| Parch+Sibsp | 혼자거나 대가족의 사람들보다 적정한 2-4인 가족이 생존율이 높다. |
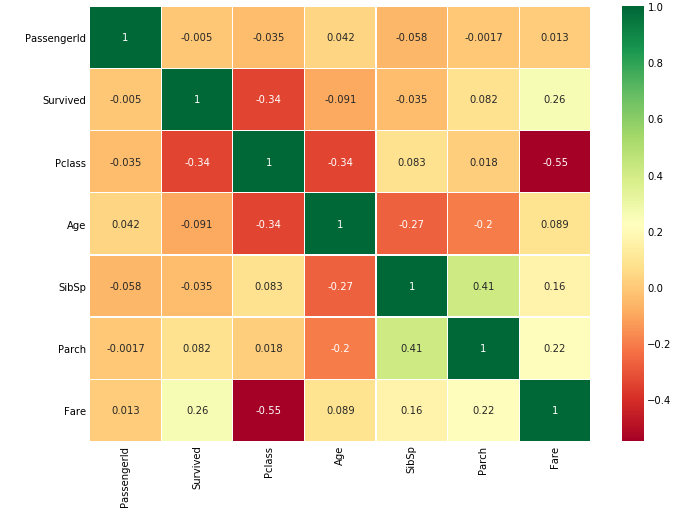
Correlation Between The Features
|
1
2
3
4
5
|
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) #data.corr()-->correlation matrix
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
2. Feature Enginering and Data Cleaning(데이터 전처리)
Age band
age는 numeric하지만 카테고리로 나눠 age 간의 수치적인 점수를 없애야 더 좋은 모델이 나올 수 있다. 그 이유는, age와 생존율에 대한 그래프를 보면 알겠지만, age가 클수록 생존율이 커지는것이 아니라, 어린이 구간(16살이하), 청년구간등 생존율이 확연하게 다르기 때문이다.
그렇다면 나이를 어떻게 카테고리로 나눌 수 있을까? 여기서는 최대 나이인 80을 기준으로 5개의 범위로 나눴다.
|
1
2
3
4
5
6
|
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
|

Family Size and Alone
Family Size= parch + sibsp로 생성. alone인 경우 size=0
|
1
2
3
4
|
data['Family_Size']=0
data['Family_Size']=data['Parch']+data['SibSp']#family size
data['Alone']=0
data.loc[data.Family_Size==0,'Alone']=1#Alone
|
Fare Range
Fare를 age처럼 categorical한 데이터로 바꿔주겠다. fare의 범위가 워낙 방대하기 때문에 pandas.qcut를 이용했다. qcut는 원하는 bins를 설정하면 그 수대로 값을 나눠준다. 여기서는 4개의 범위로 적용했다.
|
1
2
3
|
data['Fare_Range']=pd.qcut(data['Fare'],4)
data.groupby(['Fare_Range'])['Survived'].mean().to_frame().style.background_gradient(cmap='summer_r')
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

결과를 보면 확실히 fare가 증가할수록 생존확률이 높다.
Fare-> 카테고리
|
1
2
3
4
5
6
7
8
|
data['Fare_cat']=0
data.loc[data['Fare']<=7.91,'Fare_cat']=0
data.loc[(data['Fare']>7.91)&(data['Fare']<=14.454),'Fare_cat']=1
data.loc[(data['Fare']>14.454)&(data['Fare']<=31),'Fare_cat']=2
data.loc[(data['Fare']>31)&(data['Fare']<=513),'Fare_cat']=3
sns.factorplot('Fare_cat','Survived',data=data,hue='Sex')
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|

Converting string values into numeric
sex, embarked..등 카테고리를 numeric으로 변경
|
1
2
3
|
data['Sex'].replace(['male','female'],[0,1],inplace=True)
data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)
|
http://colorscripter. |
Dropping UnNeeded Features
|
1
2
3
4
5
6
7
|
data.drop(['Name','Age','Ticket','Fare','Cabin','Fare_Range','PassengerId'],axis=1,inplace=True)
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2,annot_kws={'size':20})
fig=plt.gcf()
fig.set_size_inches(18,15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

family size에 parch, sibsp는 다중 공산성을 띄기 때문에 상관관계가 높다.
3. Predictive Modeling
1)Logistic Regression
2)Support Vector Machines(Linear and radial)
3)Random Forest
4)K-Nearest Neighbours
5)Naive Bayes
6)Decision Tree
7)Logistic Regression
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
#importing all the required ML packages
from sklearn.linear_model import LogisticRegression #logistic regression
from sklearn import svm #support vector Machine
from sklearn.ensemble import RandomForestClassifier #Random Forest
from sklearn.neighbors import KNeighborsClassifier #KNN
from sklearn.naive_bayes import GaussianNB #Naive bayes
from sklearn.tree import DecisionTreeClassifier #Decision Tree
from sklearn.model_selection import train_test_split #training and testing data split
from sklearn import metrics #accuracy measure
from sklearn.metrics import confusion_matrix #for confusion matrix
train,test=train_test_split(data,test_size=0.3,random_state=0,stratify=data['Survived'])
train_X=train[train.columns[1:]]
train_Y=train[train.columns[:1]]
test_X=test[test.columns[1:]]
test_Y=test[test.columns[:1]]
X=data[data.columns[1:]]
Y=data['Survived']
# SVC
model=svm.SVC(kernel='rbf',C=1,gamma=0.1)
model.fit(train_X,train_Y)
prediction1=model.predict(test_X)
print('Accuracy for rbf SVM is ',metrics.accuracy_score(prediction1,test_Y))
# linear- SVM
model=svm.SVC(kernel='linear',C=0.1,gamma=0.1)
model.fit(train_X,train_Y)
prediction2=model.predict(test_X)
print('Accuracy for linear SVM is',metrics.accuracy_score(prediction2,test_Y))
# logistic Regression
model = LogisticRegression()
model.fit(train_X,train_Y)
prediction3=model.predict(test_X)
print('The accuracy of the Logistic Regression is',metrics.accuracy_score(prediction3,test_Y))
# Decision Tree
model=DecisionTreeClassifier()
model.fit(train_X,train_Y)
prediction4=model.predict(test_X)
print('The accuracy of the Decision Tree is',metrics.accuracy_score(prediction4,test_Y))
# KNN
model=KNeighborsClassifier()
model.fit(train_X,train_Y)
prediction5=model.predict(test_X)
print('The accuracy of the KNN is',metrics.accuracy_score(prediction5,test_Y))
# Gaussian Naive Bayes
model=GaussianNB()
model.fit(train_X,train_Y)
prediction6=model.predict(test_X)
print('The accuracy of the NaiveBayes is',metrics.accuracy_score(prediction6,test_Y))
# Random Forests
model.fit(train_X,train_Y)
prediction7=model.predict(test_X)
print('The accuracy of the Random Forests is',metrics.accuracy_score(prediction7,test_Y))
|
4. Cross Validation
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
from sklearn.model_selection import KFold #for K-fold cross validation
from sklearn.model_selection import cross_val_score #score evaluation
from sklearn.model_selection import cross_val_predict #prediction
kfold = KFold(n_splits=10, random_state=22) # k=10, split the data into 10 equal parts
xyz=[]
accuracy=[]
std=[]
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
models=[svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),KNeighborsClassifier(n_neighbors=9)
,DecisionTreeClassifier(),GaussianNB(),RandomForestClassifier(n_estimators=100)]
for i in models:
model = i
cv_result = cross_val_score(model,X,Y, cv = kfold,scoring = "accuracy")
cv_result=cv_result
xyz.append(cv_result.mean())
std.append(cv_result.std())
accuracy.append(cv_result)
new_models_dataframe2=pd.DataFrame({'CV Mean':xyz,'Std':std},index=classifiers)
new_models_dataframe2
|

plt.subplots(figsize=(12,6))
box=pd.DataFrame(accuracy,index=[classifiers])
box.T.boxplot()


Confusion Matrix
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
f,ax=plt.subplots(3,3,figsize=(12,10))
y_pred = cross_val_predict(svm.SVC(kernel='rbf'),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,0],annot=True,fmt='2.0f')
ax[0,0].set_title('Matrix for rbf-SVM')
y_pred = cross_val_predict(svm.SVC(kernel='linear'),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,1],annot=True,fmt='2.0f')
ax[0,1].set_title('Matrix for Linear-SVM')
y_pred = cross_val_predict(KNeighborsClassifier(n_neighbors=9),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[0,2],annot=True,fmt='2.0f')
ax[0,2].set_title('Matrix for KNN')
y_pred = cross_val_predict(RandomForestClassifier(n_estimators=100),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,0],annot=True,fmt='2.0f')
ax[1,0].set_title('Matrix for Random-Forests')
y_pred = cross_val_predict(LogisticRegression(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,1],annot=True,fmt='2.0f')
ax[1,1].set_title('Matrix for Logistic Regression')
y_pred = cross_val_predict(DecisionTreeClassifier(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[1,2],annot=True,fmt='2.0f')
ax[1,2].set_title('Matrix for Decision Tree')
y_pred = cross_val_predict(GaussianNB(),X,Y,cv=10)
sns.heatmap(confusion_matrix(Y,y_pred),ax=ax[2,0],annot=True,fmt='2.0f')
ax[2,0].set_title('Matrix for Naive Bayes')
plt.subplots_adjust(hspace=0.2,wspace=0.2)
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
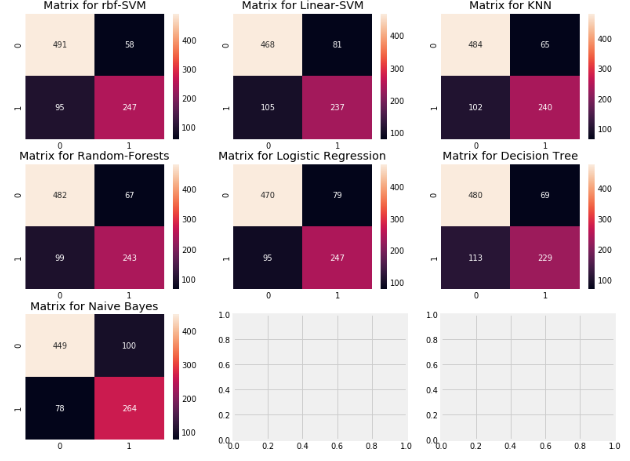
confusion 결과를 보면, rbf-SVM이 죽은 승객을 정확하게 예측할 확률은 높지만 Naive Bayes가 산 사람들을 더 정확하게 예측한다.
Hyper parameters tuning
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# SVM
from sklearn.model_selection import GridSearchCV
C=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
gamma=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]
kernel=['rbf','linear']
hyper={'kernel':kernel,'C':C,'gamma':gamma}
gd=GridSearchCV(estimator=svm.SVC(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)
# Random Forest
n_estimators=range(100,1000,100)
hyper={'n_estimators':n_estimators}
gd=GridSearchCV(estimator=RandomForestClassifier(random_state=0),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
5. Ensembling
앙상블에는 Voting classifier, Bagging, Boosting이 있는데 여기서는 Bagging과 Boosting방법을 사용해 보겠다.
bagging, boosting은 아래 링크를 참조
https://ekdud7667.tistory.com/13?category=887591
[Ensemble] 개요(Bagging, Boosting, Stacking)
아래의 포스팅은 팀블로그인 '데이터 맛집'에서 참고한 내용입니다. 팀블로그-앙상블 기법정리 [앙상블 기법 정리] 1. 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 안녕하세요,..
ekdud7667.tistory.com
Bagging
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Bagged KNN
from sklearn.ensemble import BaggingClassifier
model=BaggingClassifier(base_estimator=KNeighborsClassifier(n_neighbors=3),random_state=0,n_estimators=700)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged KNN is:',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged KNN is:',result.mean())
# Bagged Dicision Tree
model=BaggingClassifier(base_estimator=DecisionTreeClassifier(),random_state=0,n_estimators=100)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
print('The accuracy for bagged Decision Tree is:',metrics.accuracy_score(prediction,test_Y))
result=cross_val_score(model,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for bagged Decision Tree is:',result.mean())
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
Boosting
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# AdaBoost(Adaptive Boosting)
from sklearn.ensemble import AdaBoostClassifier
ada=AdaBoostClassifier(n_estimators=200,random_state=0,learning_rate=0.1)
result=cross_val_score(ada,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for AdaBoost is:',result.mean())
# Stochastic Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
grad=GradientBoostingClassifier(n_estimators=500,random_state=0,learning_rate=0.1)
result=cross_val_score(grad,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for Gradient Boosting is:',result.mean())
# XGBoost
import xgboost as xg
xgboost=xg.XGBClassifier(n_estimators=900,learning_rate=0.1)
result=cross_val_score(xgboost,X,Y,cv=10,scoring='accuracy')
print('The cross validated score for XGBoost is:' ,result.mean())
# hyperparameter tuning
n_estimators=list(range(100,1100,100))
learn_rate=[0.05,0.1,0.2,0.3,0.25,0.4,0.5,0.6,0.7,0.8,0.9,1]
hyper={'n_estimators':n_estimators,'learning_rate':learn_rate}
gd=GridSearchCV(estimator=AdaBoostClassifier(),param_grid=hyper,verbose=True)
gd.fit(X,Y)
print(gd.best_score_)
print(gd.best_estimator_)
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
Confusion Matrix for the Best Model
AdaBoost가 가장 score이 좋아, confusion matrix를 구해보았다.

Feature Importance
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
f,ax=plt.subplots(2,2,figsize=(15,12))
model=RandomForestClassifier(n_estimators=500,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,0])
ax[0,0].set_title('Feature Importance in Random Forests')
model=AdaBoostClassifier(n_estimators=200,learning_rate=0.05,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[0,1],color='#ddff11')
ax[0,1].set_title('Feature Importance in AdaBoost')
model=GradientBoostingClassifier(n_estimators=500,learning_rate=0.1,random_state=0)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,0],cmap='RdYlGn_r')
ax[1,0].set_title('Feature Importance in Gradient Boosting')
model=xg.XGBClassifier(n_estimators=900,learning_rate=0.1)
model.fit(X,Y)
pd.Series(model.feature_importances_,X.columns).sort_values(ascending=True).plot.barh(width=0.8,ax=ax[1,1],color='#FD0F00')
ax[1,1].set_title('Feature Importance in XgBoost')
plt.show()
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

결론적으로 initial, fare_cat, pclass, family_size가 공통적으로 중요한 요소이다.
또, 단독 sex보다 pclass와 결합된 sex가 차별된 중요한 요소로 보인다.
또, 공통적으로 중요한 요소에 initial이 있는데 이는 sex가 포함된 요소이기 때문에 성별이 중요하다는 것을 확인할 수 있다.
출처
'인공지능 > 캐글' 카테고리의 다른 글
| 1-3. Titanic Top 4% with ensemble (0) | 2020.04.15 |
|---|---|
| 1-1. 타이타닉 튜토리얼1 (0) | 2020.04.14 |

