앞의 내용과 마찬가지로, 1-1, 1-2에서 진행했던 EDA부분은 생략하겠다.(null값, describe, feature 그래프..)
https://ekdud7667.tistory.com/44
https://ekdud7667.tistory.com/42
데이터 그래프 부분은 위쪽을 참고를 부탁드린다.
1. Load Data & check
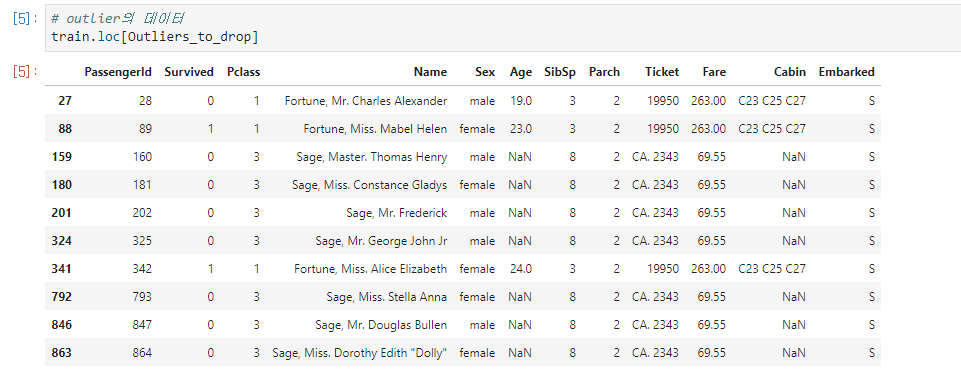
Outlier detection
featur를 반복하며 outlier를 넘는 데이터 출력 후 drop
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
IDtest= test["PassengerId"]
# Outlier detection
# feature을 반복하며 IQR 범위를 넘어가는 index를 찾는다. index가 n(2)번 이상 나온 경우 multiple_outliers에 저장해 return
def detect_outliers(df,n,features):
"""
Takes a dataframe df of features and returns a list of the indices
corresponding to the observations containing more than n outliers according
to the Tukey method.
"""
outlier_indices = []
# feature 반복
for col in features:
# 1st quartile (25%)
Q1 = np.percentile(df[col], 25)
# 3rd quartile (75%)
Q3 = np.percentile(df[col],75)
# Interquartile range (IQR)
IQR = Q3 - Q1
# outlier step
outlier_step = 1.5 * IQR
# Determine a list of indices of outliers for feature col
outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step )].index
# append the found outlier indices for col to the list of outlier indices
outlier_indices.extend(outlier_list_col)
# select observations containing more than 2 outliers
outlier_indices = Counter(outlier_indices)
multiple_outliers = list( k for k, v in outlier_indices.items() if v > n )
return multiple_outliers
# detect outliers from Age, SibSp , Parch and Fare
# outlier들의 index를 리스트 형식으로 retrun
Outliers_to_drop = detect_outliers(train,2,["Age","SibSp","Parch","Fare"])
# Drop outliers
train = train.drop(Outliers_to_drop, axis = 0).reset_index(drop=True)
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
Joining train and test set
많은 양의 데이터로 분석하고, 결측치를 보다 정확하게 채우기 위해서 train, test를 join 시킨 데이터를 사용했다.
3. Feature Analysis
4. Filling Missing Values
Age
데이터를 보면 성별과 나이는 별 차이가 없고, sibsp와 class의 숫자가 커질수록 어림
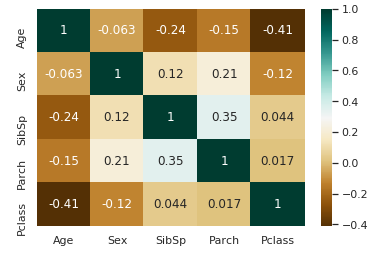
상관관계를 봐도 parch, pcalss, sibsp는 음의 상관관계를 가진다. 따라서 parch, pcalss sibsp를 이용해 중앙값으로 age의 null값을 채울 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# Filling missing value of Age
## Fill Age with the median age of similar rows according to Pclass, Parch and SibSp
# Index of NaN age rows
index_NaN_age = list(dataset["Age"][dataset["Age"].isnull()].index)
for i in index_NaN_age :
# sibsp, parch, pcalss의 공통된 중앙값이 있으면 그대로 채우고, 없으면 전체 dataset의 age 중앙값으로 채움
age_med = dataset["Age"].median()
age_pred = dataset["Age"][((dataset['SibSp'] == dataset.iloc[i]["SibSp"]) & (dataset['Parch'] == dataset.iloc[i]["Parch"]) & (dataset['Pclass'] == dataset.iloc[i]["Pclass"]))].median()
if not np.isnan(age_pred) :
dataset['Age'].iloc[i] = age_pred
else :
dataset['Age'].iloc[i] = age_med
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
5. Feature engineering
Name/ Title
Name을 Title(이름 성)으로 변경
|
1
2
3
4
5
6
7
8
|
# Get Title from Name
dataset_title = [i.split(",")[1].split(".")[0].strip() for i in dataset["Name"]]
dataset["Title"] = pd.Series(dataset_title)
# Convert to categorical values Title
dataset["Title"] = dataset["Title"].replace(['Lady', 'the Countess','Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset["Title"] = dataset["Title"].map({"Master":0, "Miss":1, "Ms" : 1 , "Mme":1, "Mlle":1, "Mrs":1, "Mr":2, "Rare":3})
dataset["Title"] = dataset["Title"].astype(int)
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
Family Size
Family size= sibsp + parch + 1(자기자신)으로 정의하고, 카테고리화 시켰다.
Family size는 지난번 게시글과 비슷하게 소규모 가족들의 생존율이 가장 높았다.
사실, sibsp와 parch가 family size에 종속되어 있어 다중공산성이라는 문제가 생긴다. 때문에 sibsp, parch를 왜 삭제안하고 분석한지 이해가 되지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# Create a family size descriptor from SibSp and Parch
dataset["Fsize"] = dataset["SibSp"] + dataset["Parch"] + 1
# Create new feature of family size
dataset['Single'] = dataset['Fsize'].map(lambda s: 1 if s == 1 else 0)
dataset['SmallF'] = dataset['Fsize'].map(lambda s: 1 if s == 2 else 0)
dataset['MedF'] = dataset['Fsize'].map(lambda s: 1 if 3 <= s <= 4 else 0)
dataset['LargeF'] = dataset['Fsize'].map(lambda s: 1 if s >= 5 else 0)
# convert to indicator values Title and Embarked
dataset = pd.get_dummies(dataset, columns = ["Title"])
dataset = pd.get_dummies(dataset, columns = ["Embarked"], prefix="Em")
|
Cabin
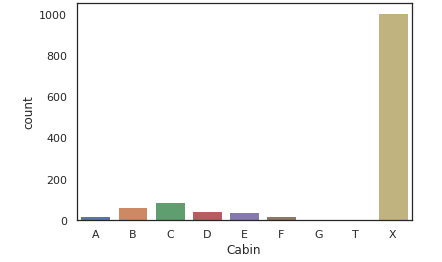
Cabin은 전체 데이터 중 결측치인 값이 1007개로 매우 많다. 따라서 결측치를 'x'라고 잡고 그래프를 그려보겠다.
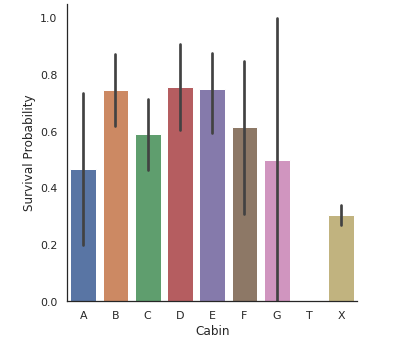
X는 결측치 데이터들로만 이뤄져 있으며, X가 가장 많은것을 확인할 수 있다.
사람들은 X로 가장 많이 탑승했지만 생존율은 가장 낮다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# Replace the Cabin number by the type of cabin 'X' if not
dataset["Cabin"] = pd.Series([i[0] if not pd.isnull(i) else 'X' for i in dataset['Cabin'] ])
g = sns.countplot(dataset["Cabin"],order=['A','B','C','D','E','F','G','T','X'])
# 첫번째 글자는 데스크를 의미하기 때문에 이 글자만 사용
g = sns.factorplot(y="Survived",x="Cabin",data=dataset,kind="bar",order=['A','B','C','D','E','F','G','T','X'])
g = g.set_ylabels("Survival Probability")
#x로 제일 많은 사람이 탑승했지만, 생존율은 낮은걸 확인할 수 있다.
# onehotencording
dataset = pd.get_dummies(dataset, columns = ["Cabin"],prefix="Cabin")
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
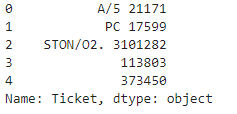
Ticket
Ticket의 데이터는 무척 다양하다. 아래가 ticket의 데이터 모양인데, 이 데이터를 공백 혹은 .를 기준으로 앞글자만 따와 사용했다. 앞부분만 자르면 unique값은 37개
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
## Treat Ticket by extracting the ticket prefix. When there is no prefix it returns X.
Ticket = []
for i in list(dataset.Ticket):
if not i.isdigit() :
Ticket.append(i.replace(".","").replace("/","").strip().split(' ')[0]) #Take prefix
else:
Ticket.append("X")
dataset["Ticket"] = Ticket
dataset["Ticket"].head()
# Create categorical values for Pclass
dataset["Pclass"] = dataset["Pclass"].astype("category")
dataset = pd.get_dummies(dataset, columns = ["Pclass"],prefix="Pc")
# Drop useless variables
dataset.drop(labels = ["Ticket"], axis = 1, inplace = True)
dataset.drop(labels = ["PassengerId"], axis = 1, inplace = True)
|

6. Modeling
cross validate models
- SVC
- Decision Tree
- AdaBoost
- Random Forest
- Extra Trees
- Gradient Boosting
- Multiple layer perceprton(neural network)
- KNN
- Logistic regression
- Linear Discriminant Analysis
Extra Trees에 대해 잠깐 찾아봤다. Extra Trees의 다른말은 익스트림 랜덤 트리로, 랜덤 포레스트보다 더 극단적으로 무작위 한 특징을 가지고 있다. 결정 트리 형성을 위해 feature을 선택할 때 무작위성의 특징을 가진다. 다시 말해, 다른 모델처럼 최적의 임계값을 찾아 분할하는 것이 아닌, 후보 특성을 사용해 무작위로 분할한 다음 최상의 분할을 선택한다.
엑스트라 트리는 랜덤 포레스트 보다 훨씬 빠른데, 노드의 feature마다 최적의 임계값을 찾는 시간을 없앨 수 있기 때문이다.
엑스트라 트리는 랜덤 포레스트보다 전반적으로 feature들의 중요도를 더 높게 평가하는데, 이는 엑스트라 트리가 더 폭넓은 시각으로 feature들을 평가한다고 생각하면 된다.
글로만 설명하면 이해가 되지 않아 아래에 링크를 걸어두겠다. 아래의 링크는 에이다부스트인데, boost가 어떻게 작동되는지 확인할 수 있다. 아래의 절차에서 임계값을 찾는게 복잡한데 이를 랜덤하게 뽑아 시간을 엄청나게 단축시킨다.
https://ekdud7667.tistory.com/47
Adaboost(에이다부스트)
Adaboost는 Random Forest의 Boost모델 일종이다. Boost와 Bagging에 대한 설명은 아래 링크를 걸어두겠다. https://ekdud7667.tistory.com/13?category=887591 [Ensemble] 개요(Bagging, Boosting, Stacking) 아..
ekdud7667.tistory.com
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
## Separate train dataset and test dataset
train = dataset[:train_len]
test = dataset[train_len:]
test.drop(labels=["Survived"],axis = 1,inplace=True)
## Separate train features and label
train["Survived"] = train["Survived"].astype(int)
Y_train = train["Survived"]
X_train = train.drop(labels = ["Survived"],axis = 1)
# Cross validate model with Kfold stratified cross val
kfold = StratifiedKFold(n_splits=10)
# Modeling step Test differents algorithms
random_state = 2
classifiers = []
classifiers.append(SVC(random_state=random_state))
classifiers.append(DecisionTreeClassifier(random_state=random_state))
classifiers.append(AdaBoostClassifier(DecisionTreeClassifier(random_state=random_state)
,random_state=random_state,learning_rate=0.1))
classifiers.append(RandomForestClassifier(random_state=random_state))
classifiers.append(ExtraTreesClassifier(random_state=random_state))
classifiers.append(GradientBoostingClassifier(random_state=random_state))
classifiers.append(MLPClassifier(random_state=random_state))
classifiers.append(KNeighborsClassifier())
classifiers.append(LogisticRegression(random_state = random_state))
classifiers.append(LinearDiscriminantAnalysis())
cv_results = []
for classifier in classifiers :
cv_results.append(cross_val_score(classifier, X_train, y = Y_train, scoring = "accuracy", cv = kfold, n_jobs=4))
cv_means = []
cv_std = []
for cv_result in cv_results:
cv_means.append(cv_result.mean())
cv_std.append(cv_result.std())
cv_res = pd.DataFrame({"CrossValMeans":cv_means,"CrossValerrors": cv_std,
"Algorithm":["SVC","DecisionTree","AdaBoost","RandomForest","ExtraTrees","GradientBoosting",
"MultipleLayerPerceptron","KNeighboors","LogisticRegression","LinearDiscriminantAnalysis"]})
g = sns.barplot("CrossValMeans","Algorithm",data = cv_res, palette="Set3",orient = "h",**{'xerr':cv_std})
g.set_xlabel("Mean Accuracy")
g = g.set_title("Cross validation scores")
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
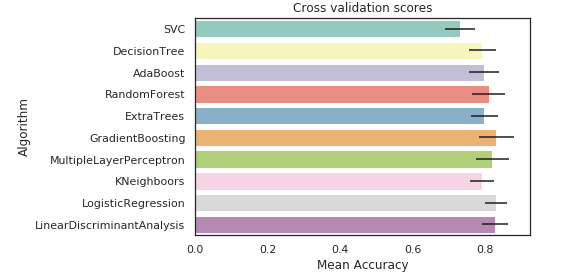
필자가 사용한 데이터는 movie lens 100k이지만, 원본 게시자는 가장 큰 데이터를 사용해서 score가 다른점을 감안해야 한다.
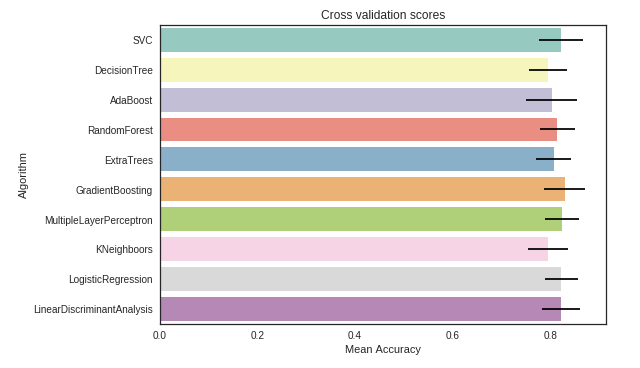
원본 결과를 보고, SVC, AdaBoost, RandomForest, ExtraTrees, GradientBoosting Classifiers를 사용해 ensemble modeling을 했다.
Hyperparameter tunning for best models
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
# Adaboost
DTC = DecisionTreeClassifier()
adaDTC = AdaBoostClassifier(DTC, random_state=7)
ada_param_grid = {"base_estimator__criterion" : ["gini", "entropy"],
"base_estimator__splitter" : ["best", "random"],
"algorithm" : ["SAMME","SAMME.R"],
"n_estimators" :[1,2],
"learning_rate": [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3,1.5]}
gsadaDTC = GridSearchCV(adaDTC,param_grid = ada_param_grid, cv=kfold, scoring="accuracy", n_jobs= 4, verbose = 1)
gsadaDTC.fit(X_train,Y_train)
ada_best = gsadaDTC.best_estimator_
#ExtraTrees
ExtC = ExtraTreesClassifier()
## Search grid for optimal parameters
ex_param_grid = {"max_depth": [None],
"max_features": [1, 3, 10],
"min_samples_split": [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
gsExtC = GridSearchCV(ExC,param_grid = ex_param_grid, cv=kfold, scoring="accuracy", n_jobs= 4, verbose = 1)
gsExtC.fit(X_train,Y_train)
ExtC_best = gsExtC.best_estimator_
# Best score
gsExtC.best_score_
# RFC Parameters tunning
RFC = RandomForestClassifier()
## Search grid for optimal parameters
rf_param_grid = {"max_depth": [None],
"max_features": [1, 3, 10],
"min_samples_split": [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
gsRFC = GridSearchCV(RFC,param_grid = rf_param_grid, cv=kfold, scoring="accuracy", n_jobs= 4, verbose = 1)
gsRFC.fit(X_train,Y_train)
RFC_best = gsRFC.best_estimator_
# Best score
gsRFC.best_score_
# Gradient boosting tunning
GBC = GradientBoostingClassifier()
gb_param_grid = {'loss' : ["deviance"],
'n_estimators' : [100,200,300],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [4, 8],
'min_samples_leaf': [100,150],
'max_features': [0.3, 0.1]
}
gsGBC = GridSearchCV(GBC,param_grid = gb_param_grid, cv=kfold, scoring="accuracy", n_jobs= 4, verbose = 1)
gsGBC.fit(X_train,Y_train)
GBC_best = gsGBC.best_estimator_
# Best score
gsGBC.best_score_
### SVC classifier
SVMC = SVC(probability=True)
svc_param_grid = {'kernel': ['rbf'],
'gamma': [ 0.001, 0.01, 0.1, 1],
'C': [1, 10, 50, 100,200,300, 1000]}
gsSVMC = GridSearchCV(SVMC,param_grid = svc_param_grid, cv=kfold, scoring="accuracy", n_jobs= 4, verbose = 1)
gsSVMC.fit(X_train,Y_train)
SVMC_best = gsSVMC.best_estimator_
# Best score
gsSVMC.best_score_
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
Plot learning curves
learning curve로 overfitting을 확인하기 위함
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=-1, train_sizes=np.linspace(.1, 1.0, 5)):
"""Generate a simple plot of the test and training learning curve"""
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
g = plot_learning_curve(gsRFC.best_estimator_,"RF mearning curves",X_train,Y_train,cv=kfold)
g = plot_learning_curve(gsExtC.best_estimator_,"ExtraTrees learning curves",X_train,Y_train,cv=kfold)
g = plot_learning_curve(gsSVMC.best_estimator_,"SVC learning curves",X_train,Y_train,cv=kfold)
g = plot_learning_curve(gsadaDTC.best_estimator_,"AdaBoost learning curves",X_train,Y_train,cv=kfold)
g = plot_learning_curve(gsGBC.best_estimator_,"GradientBoosting learning curves",X_train,Y_train,cv=kfold)
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
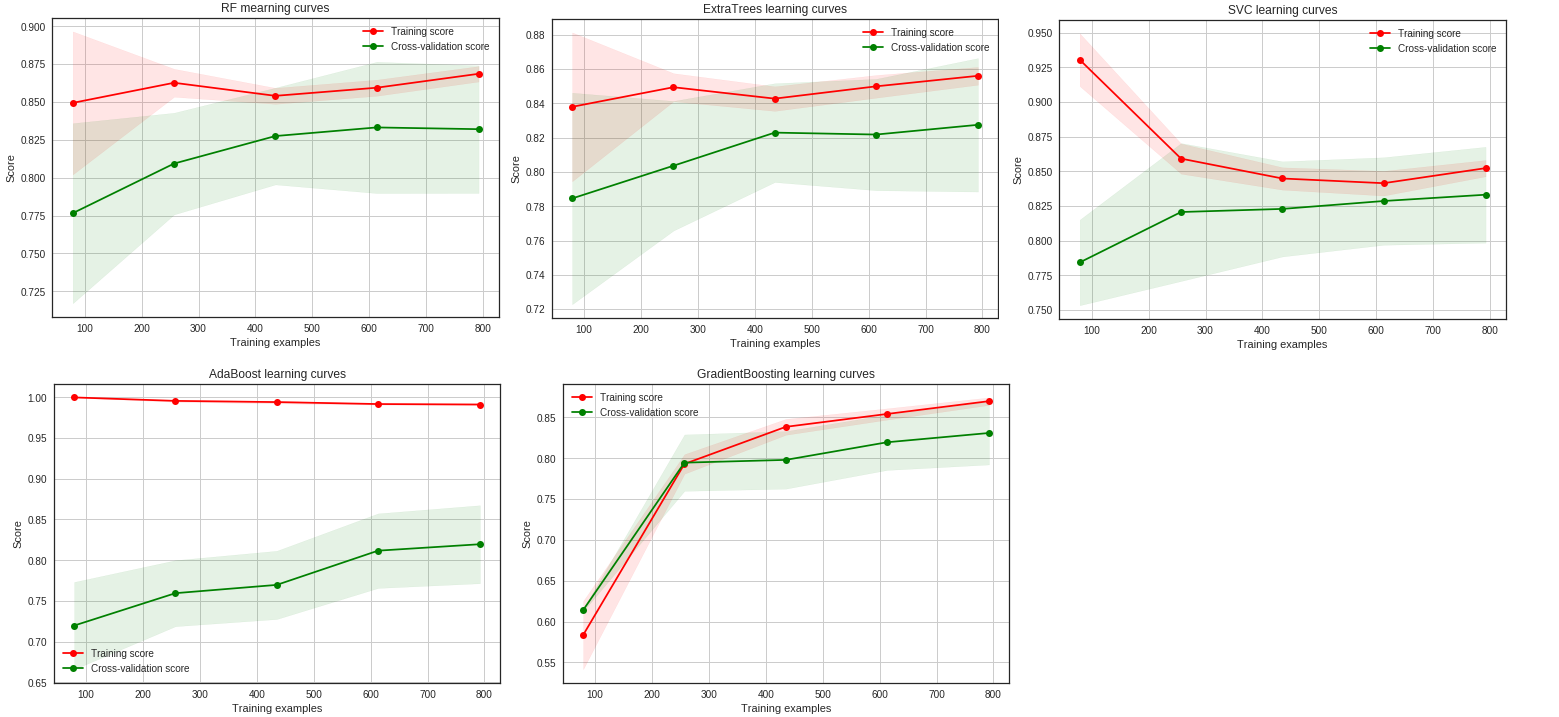
결과를 보면 Gradient, Adaboost는 overfitting이 되어있다. 반면에, SVD와 ExtraTrees classifiers는 train을 할수록 더 나아진 결과를 보이고 overfitting의 모습이 보이지 않는다.
earily stopping이라고 하는 방법은 test score가 더이상 개선되지 않고, 정체되거나 오히려 떨어질때 학습을 끝낸다. 사실 earily stopping 관점에서 보면 adaboost는 계속해서 test score가 올라가고 있으므로 overfitting이라고 할 수 없다.
사실 overfitting과 underfitting은 매우 주관적인 판단이 필요하며, train score와 test score의 크기차이, test score의 수렴등을 확인하여 판단해야한다. 만약 overfitting이 의심된다면, 데이터를 직접 뽑아 특정 데이터만 학습을 못한다던가 예측값이 한 분포로 몰려있다던가 하는걸 직접 확인해야한다.
Feature importance of tree based classifiers
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
nrows = ncols = 2
fig, axes = plt.subplots(nrows = nrows, ncols = ncols, sharex="all", figsize=(15,15))
names_classifiers = [("AdaBoosting", ada_best),("ExtraTrees",ExtC_best),("RandomForest",RFC_best),("GradientBoosting",GBC_best)]
nclassifier = 0
for row in range(nrows):
for col in range(ncols):
name = names_classifiers[nclassifier][0]
classifier = names_classifiers[nclassifier][1]
indices = np.argsort(classifier.feature_importances_)[::-1][:40]
g = sns.barplot(y=X_train.columns[indices][:40],x = classifier.feature_importances_[indices][:40] , orient='h',ax=axes[row][col])
g.set_xlabel("Relative importance",fontsize=12)
g.set_ylabel("Features",fontsize=12)
g.tick_params(labelsize=9)
g.set_title(name + " feature importance")
nclassifier += 1
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
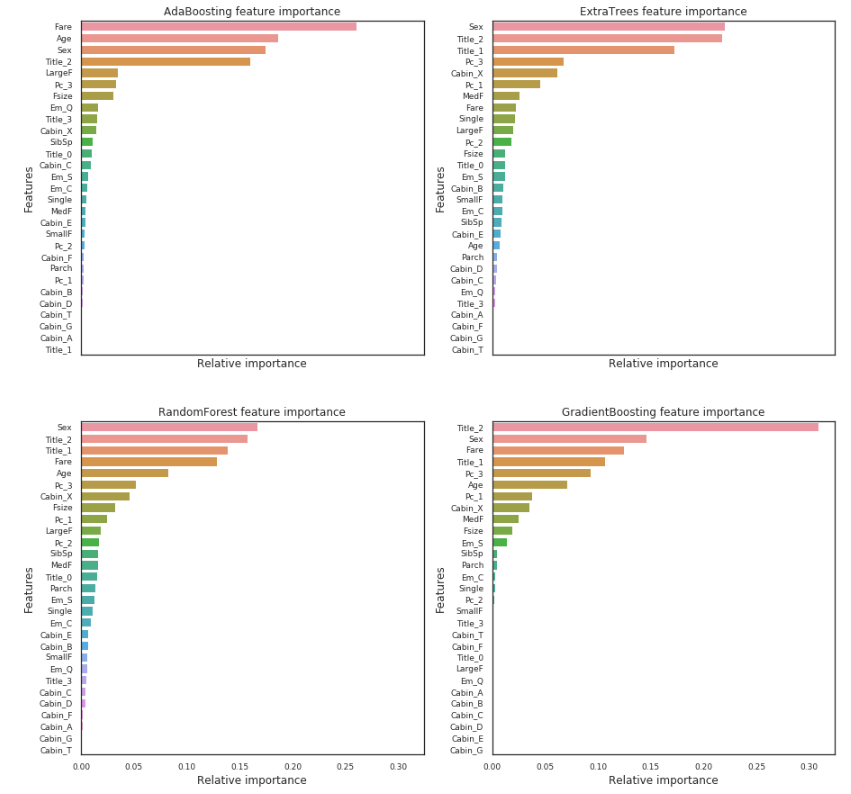
공통적으로 Fare, Title_2, Age, Sex는 높은 중요도를 가진다.
Title_2(이름 성)는 Sex와 높은 상관관계를 가진다.
- Pc_1, Pc_2, Pc_3 and Fare refer to the general social standing of passengers.
- Sex and Title_2 (Mrs/Mlle/Mme/Miss/Ms) and Title_3 (Mr) refer to the gender.
- Age and Title_1 (Master) refer to the age of passengers.
- Fsize, LargeF, MedF, Single refer to the size of the passenger family.
According to the feature importance of this 4 classifiers, the prediction of the survival seems to be more associated with the Age, the Sex, the family size and the social standing of the passengers more than the location in the boat.
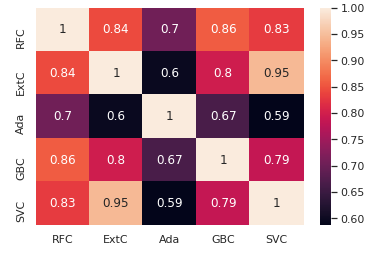
The prediction seems to be quite similar for the 5 classifiers except when Adaboost is compared to the others classifiers.
The 5 classifiers give more or less the same prediction but there is some differences. Theses differences between the 5 classifier predictions are sufficient to consider an ensembling vote.
Ensemble Modeling
combining models
voting soft버전으로 modeling
|
1
2
3
4
5
6
7
8
|
votingC = VotingClassifier(estimators=[('rfc', RFC_best), ('extc', ExtC_best),
('svc', SVMC_best), ('adac',ada_best),('gbc',GBC_best)], voting='soft', n_jobs=4)
votingC = votingC.fit(X_train, Y_train)
test_Survived = pd.Series(votingC.predict(test), name="Survived")
results = pd.concat([IDtest,test_Survived],axis=1)
results.to_csv("ensemble_python_voting.csv",index=False)
|
출처
https://www.kaggle.com/yassineghouzam/titanic-top-4-with-ensemble-modeling
'인공지능 > 캐글' 카테고리의 다른 글
| 1-2. EDA To Prediction (0) | 2020.04.15 |
|---|---|
| 1-1. 타이타닉 튜토리얼1 (0) | 2020.04.14 |

