Adaboost는 Random Forest의 Boost모델 일종이다. Boost와 Bagging에 대한 설명은 아래 링크를 걸어두겠다.
https://ekdud7667.tistory.com/13?category=887591
[Ensemble] 개요(Bagging, Boosting, Stacking)
아래의 포스팅은 팀블로그인 '데이터 맛집'에서 참고한 내용입니다. 팀블로그-앙상블 기법정리 [앙상블 기법 정리] 1. 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 안녕하세요,..
ekdud7667.tistory.com
개념
아래의 그림처럼 +와 -를 Adaboost를 이용해 나눠보자.
그림에서는 왼쪽 +를 모두 맞췄지만 오른쪽 + 3개를 맞추지 못했다. 맞추지 못한 +들에게 높은 가중치를 두겠다.

높은 가중치를 받은 데이터들을 잘 맞추기 위해서 다음과 같은 분류선이 생겼다. 하지만, 왼쪽 - 3개를 맞추지 못했고, 이전과 같이 -에 큰 가중치를 주겠다.

그 결과 다음과 같은 분류선이 만들어진다.

Random Forest처럼 3개의 분류기를 모두 합쳐 결과를 낸다.
결과는 +와 -를 유연하고 완벽하게 분류한다.

구조를 조금 다르게 살펴보자
Adaboost는 한개의 노드와 2개의 잎을 가지는 stump로 이뤄져있다. 즉, 하나의 feature로 2개의 데이터를 분류하는 구조인데, 나중에 예시를 보면서 stump를 더 자세히 설명하겠다.
Adaboost는 모든 stump를 똑같은 가중치를 두지 않고, 다른 가중치를 두어 stump를 합친다.

작동 예시

위와 같은 데이터가 있다고 생각해보자. 먼저 sample weight는 동일하게 1/8씩 가진다.
첫번째 stump(Chest Pain)을 만들어보자.

Chest Pain은 Label(Hear Disease)가 'Yes' 'No' 두개로 나뉜다. Yes Heart Disease 리프를 살펴보자. Label이 Yes이고, Chest또한 Yes인 경우는 1,3,4열인 3개이다. 이렇게 리프를 채우면 하나의 stump가 만들어진다.
위의 과정을 반복하여 모든 feature(Chest Pain, Blocked Arteries, Patient Weight)에 대한 stump를 만들어보면 다음과 같다.

각 Stump의 지니 계수를 구하고, 지니 계수가 가장 작은 stump를 개선시켜 보겠다.
* tree종류의 모델은 지니계수로 feature importance를 뽑아낸다.
Amount of say 구하기
정보량을 수치화 하기위해 amount of say를 구해야한다.
Weight라는 feature에서 틀린 정보는 1개만 존재한다.
따라서 Total Error는 1/8이 된다.



위의 그래프는 Amount of say의 분포이다. total error가 0에 가까울수록 큰 양수가 되고, 1에 가까울수록 극단적인 음수가 된다. 이 뜻은 total error가 0이라면 항상 맞춘다는 뜻이고, 0.5라면 값이 0인 즉, 의미없는 분류가 된다는 뜻이다.
다르게 말하자면, 0.5 score를 가지는 모델은 아무 의미가 없기 때문에, 데이터셋을 처음처럼 weight를 동등하게 준다. 반대로 100개중에 1개만 틀린 데이터셋은 정보량이 큰 양수값을 가지게되어 엄청나게 큰 weight를 받아 틀린값 1개에 치중되어 학습을 한다.
반대로 100개중 99개를 틀린 데이터셋은 틀린 데이터보다는 맞은 데이터에 더 큰 weight를 준다. 너무 underfitting이 되어 더 보편적인 학습을 위함인것 같다.
위의 문제에서 total error =1/8을 대입해보면 amount of say가 나온다.


Amount of say= 0.97이고 그래프에서는 화살표에 표시된 지점이다.
가중치 설정
앞의 개요에서 못맞춘 데이터에게 높은 가중치를 둔다고했다. 그렇다면 가중치를 어떻게 둬야할까?
Weight가 못맞춘 데이터에 대해 가중치를 구해보자.

가중치는 다음 공식을 적용하면 New Sample Weight = (1/8) * e^(0.97) = (1/8) * 2.64 = 0.33가 나온다.
기존에 1/8 (0.125)보다 훨씬 높은 결과이다.

맞춘 데이터는 지수의 분포만 바꾼 공식으로 적용하면 된다.

그 결과 새로운 weight는 기존의 weight보다 못맞춘 데이터에게 높은 weight를 주고, 맞춘 데이터에게 낮은 weight를 줬다.
여기서 weight의 합이 항상 1이 되야 하기 때문에 Norm해줘 Norm-weight를 구해준다.
새로운 테이블 생성
위의 결과를 바탕으로 새로운 테이블을 만든다.
만드는 방법은 norm_weight의 누적값을 이용해 랜덤하게 샘플링한다.
만약 랜덤 샘플링을 했을 때, 0~0.07의 값이 나오면 첫번째 데이터가, 0.07~0.14가 나오면 두번째 데이터, 0.21~0.7(0.49)이 나오면 4번째 데이터가 선택된다. 즉, weight가 가장 큰 4번째 데이터가 여러번 뽑힐 확률이 높다.
실제로 4번째 데이터가 4번이나 포함되었다. 이렇게 데이터의 가중치를 두고, 새로워진 테이블에 중복이 됨으로써 boost모델로 적용될 수 있는것이다. 이후, 만들어진 데이터로 처음부터 돌아가 반복한다.

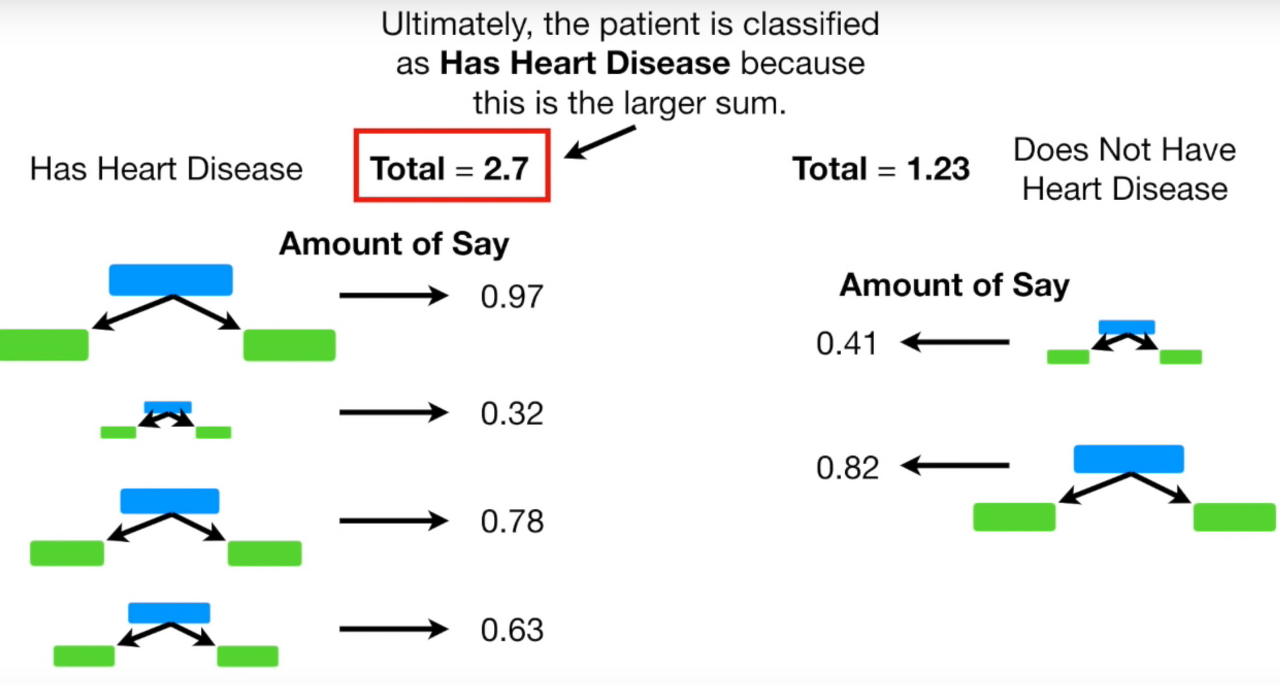
최종 결과
결과를 보면 Label이 'Yes'인 경우(Has Heart Disease) total amount of say가 2.7로 더 크기 때문에 Yes라고 결론을 내린다.
출처
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-14-AdaBoost
'인공지능 > 스터디' 카테고리의 다른 글
| Embedding (0) | 2020.06.03 |
|---|---|
| SVM(2): Kernel, polynomial Kernel, Radial Kernel(RBF) (0) | 2020.04.23 |
| SVM(Support Vector Machine)(1) (2) | 2020.04.15 |
| KNN CF(Collaborative Filtering) 구현 (0) | 2020.04.14 |
| 최대우도추정 (0) | 2020.04.14 |



